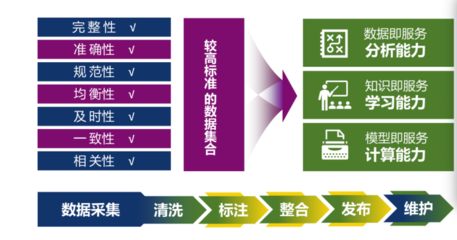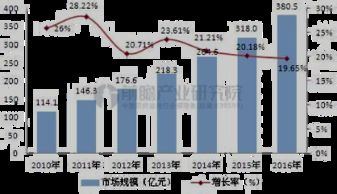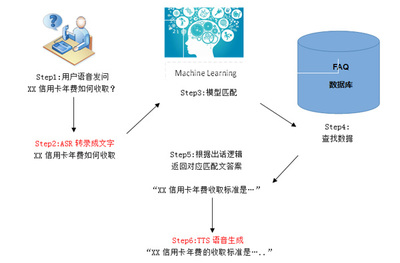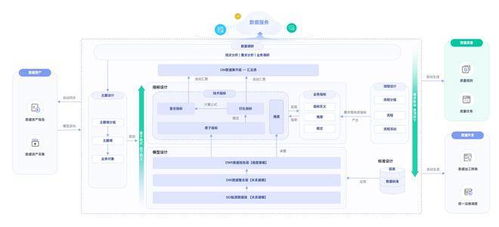
亞馬遜云科技宣布為旗下的三種核心數據分析服務——Amazon Redshift、Amazon EMR和Amazon MSK正式推出無服務器功能,標志著其在數據處理服務領域邁出了重要一步。這一創新舉措旨在進一步降低企業進行大規模數據分析的門檻,讓用戶能夠更專注于業務邏輯而非底層基礎設施的管理。
Amazon Redshift的無服務器化使得用戶無需預置和管理數據倉庫集群,即可按需自動擴展計算資源,從而高效地運行分析查詢。用戶只需為實際執行的查詢付費,這不僅大幅降低了成本,也簡化了運維工作。對于工作負載波動較大的場景,如季節性業務報表或突發性數據分析任務,這一功能顯得尤為實用。
Amazon EMR的無服務器選項允許用戶直接運行大數據框架(如Apache Spark和Hive),無需手動配置、優化或擴展集群。用戶提交作業后,系統會自動分配資源并在完成后釋放,實現了真正意義上的彈性計算。這加速了數據處理流程,特別適合間歇性的大數據處理任務,如日志分析、數據轉換和機器學習模型訓練。
Amazon MSK的無服務器功能為Apache Kafka提供了全托管的流式數據處理體驗。用戶無需管理Kafka集群,即可輕松構建實時數據管道,用于事件驅動型應用、監控和實時分析。該服務自動處理擴展、修補和監控,確保了高可用性和低延遲,幫助企業快速響應市場變化。
整體而言,亞馬遜云科技此次推出的無服務器功能,通過將底層基礎設施抽象化,顯著提升了數據分析服務的敏捷性和成本效益。企業用戶現在能夠更靈活地應對多樣化的數據處理需求,從批量分析到實時流處理,都能以按需付費的方式高效完成。這不僅順應了云計算領域“無服務器優先”的趨勢,也進一步鞏固了亞馬遜云科技在數據分析市場的領先地位,為數字化轉型注入了新動力。隨著無服務器技術的持續演進,我們可以期待更智能、更自動化的數據處理解決方案涌現,推動各行各業的數據驅動創新。